Storing 1 TB in Virtual Memory on a 64 GB Machine with Chronicle Queue
As Java developers, we often face the challenge of handling very large datasets within the constraints of the Java Virtual Machine (JVM). When the heap size grows significantly—often beyond 32 GB—garbage collection (GC) pause times can escalate, leading to performance degradation. This article explores how Chronicle Queue enables the storage and efficient access of a 1 TB dataset on a machine with only 64 GB of RAM.
The Challenge of Large Heap Sizes
Using standard JVMs like Oracle HotSpot or OpenJDK, increasing the heap size to accommodate large datasets can result in longer GC pauses. These pauses occur because the garbage collector requires more time to manage the larger heap, which can negatively impact application responsiveness.
One solution is to use a concurrent garbage collector, such as the one provided by Azul Zing, designed to handle larger heap sizes while reducing GC pause times. However, this approach may only scale well when the dataset is within the available main memory.
Handling Datasets Larger Than Main Memory
What if your dataset is larger than your machine's main memory? In such cases, relying on the heap is not feasible. Off-heap data stores become essential. While databases or NoSQL solutions can handle large datasets, they often introduce significant latency, which may not be acceptable for high-performance applications.
Introducing Chronicle Queue
Chronicle Queue provides a persisted, off-heap data store that can be accessed by multiple JVMs on the same server. It leverages memory-mapped files to manage large datasets efficiently. But how does it perform when the dataset size exceeds the available RAM?
In this article, we'll examine Chronicle Queue's performance when handling a 1 TB dataset on a machine with 64 GB of memory, focusing on sequential access patterns.
What Does a 1 TB JVM Look Like?
First, let's see what a JVM managing over 1 TB of data looks like on a machine with 64 GB of RAM.
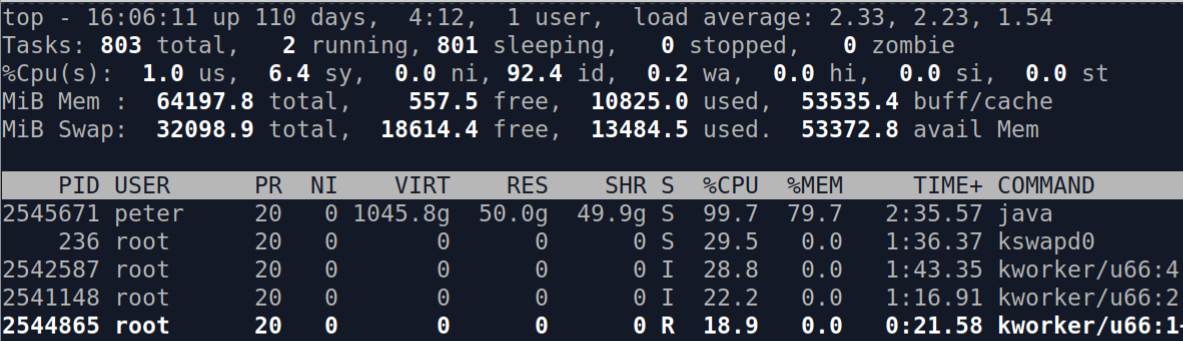
In the top output above, the JVM's virtual memory size (VIRT) is reported as 1,045.8 g, while the resident set size (RES) is only 50.0 g. This means that although the JVM addresses over 1 TB of data, only about 50 GB is actually loaded into physical memory at any given time. This is possible because Chronicle Queue uses memory-mapped files, allowing the operating system to handle virtual memory efficiently.
Performance Analysis: Does It Slow Down?
A common concern is that managing datasets larger than the main memory will degrade performance dramatically. If you attempted to create a 1 TB heap on a 64 GB machine, the JVM would likely fail to start or render the machine unusable due to excessive swapping. However, Chronicle Queue's off-heap approach minimizes this issue.
Writing and Reading Data
In our test, we perform the following steps:
- Write bursts of 1 GB consisting of 1 KiB messages.
- Perform a sync operation to flush data to disk.
- Read the data back sequentially.
The underlying disk can sustain about 630 MB/s. Writing 1 GB of data takes consistently less than 2 seconds, even as the total dataset size grows beyond the physical memory limit.
Consistent Write Performance
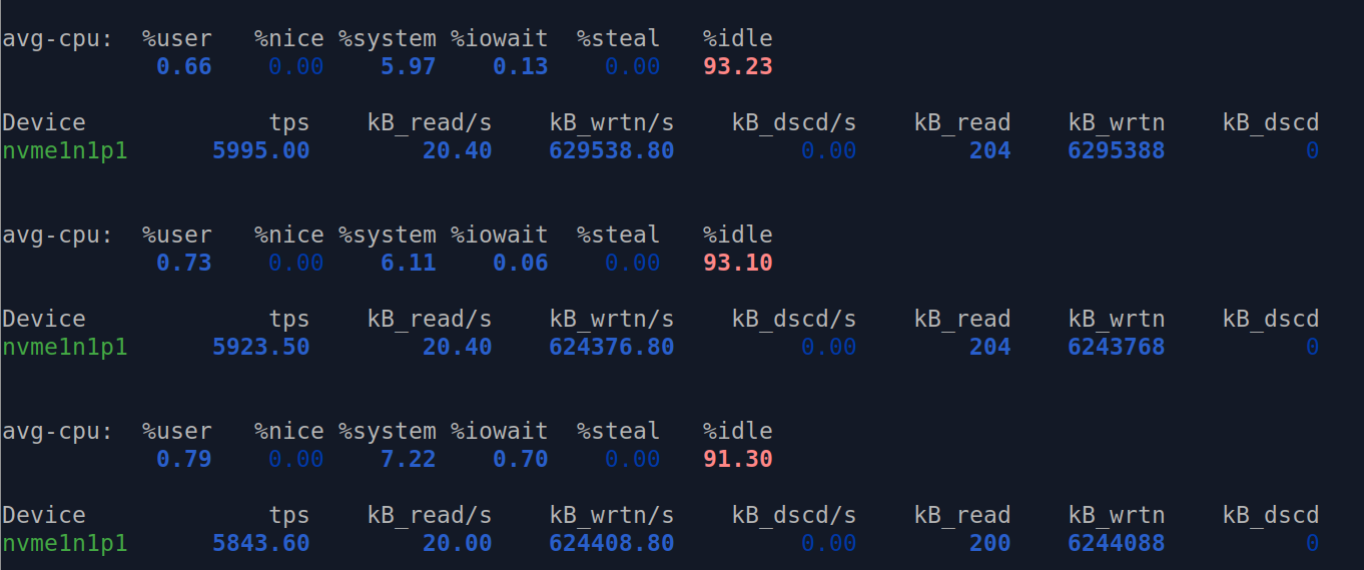
Minimal Write Slowdown
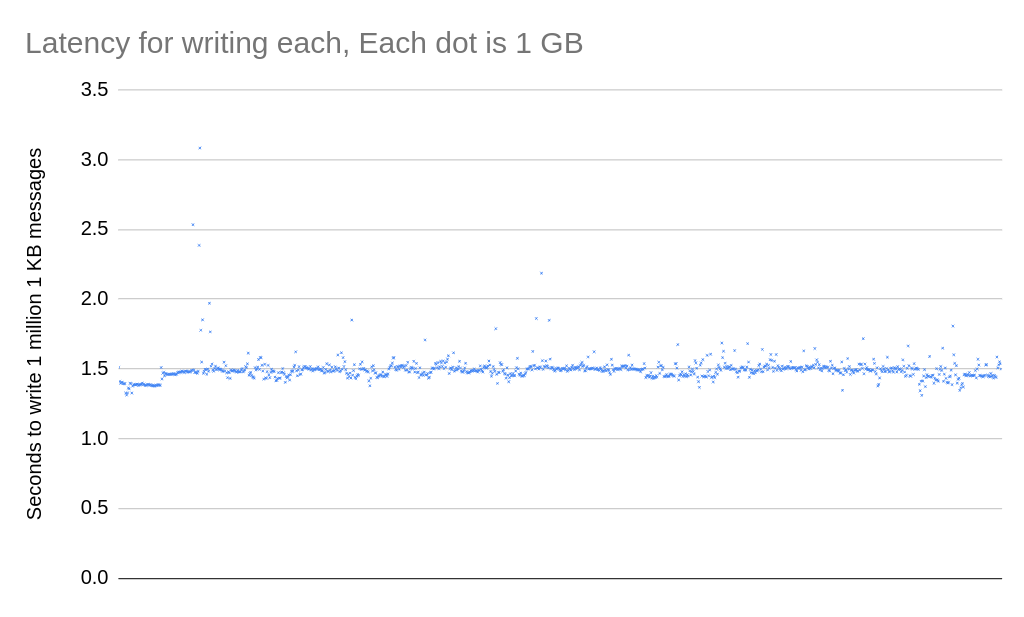
Writing 1 GB of data takes:
- An average of 1.3 seconds for the first 64 GB.
- An average of 1.5 seconds beyond 64 GB.
The slight increase in write time is minimal considering the dataset size and is acceptable for applications requiring high throughput.
Comparison with Traditional Databases
Consider the alternative of inserting 1 million records (approximately 1 GB) into a traditional database and querying them back. This process would likely take significantly longer and consume more resources. With Chronicle Queue, you can read 1 GB of records in around 70 ms using a single thread, offering a substantial performance advantage.
Conclusion
Chronicle Queue performs exceptionally well when handling datasets that exceed the main memory size. It maintains low GC pause times and efficient data access speeds by utilising off-heap memory and memory-mapped files. This makes it an ideal solution for large data volume processing applications without significant performance penalties.
Try It Yourself
You can experiment with this test by accessing the following code: RunLargeQueueMain.java
For more information on Chronicle Queue, visit the GitHub repository or the Chronicle Queue product page.
What Does the Enterprise Version Offer?
Chronicle Queue Enterprise offers additional features, such as:
- Replication across multiple servers for Fail Over and Disaster Recovery
- C++, Rust, Python implementations
- Tuning options to reduce latency jitter
- Support for Windows, macOS, and Linux
Share Your Thoughts
Have you faced challenges managing large datasets in Java? What solutions have you found effective? Feel free to share your experiences and join the discussion.
Note: Currently, having a queue larger than the main memory only works on Unix-based systems. On Windows, each cycle (e.g., a day's worth of data) must fit into the main memory. We aim to address this limitation in future updates.
Comments
Post a Comment