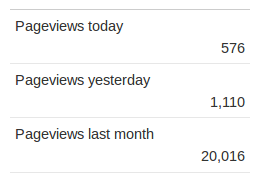
Synchronized vs Lock performance
Overview There are a number of articles on whether synchronized or Locks are faster. There appear to be opinions in favour of either option. In this article I attempt to show how you can achieve different views depending on how you benchmark the two approaches. I have included AtomicInteger to see how a volatile field compares. What are some of the differences The synchronized keyword has naturally built in language support. This can mean the JIT can optimise synchronised blocks in ways it cannot with Locks. e.g. it can combine synchronized blocks. The Lock has additional method such as tryLock which is not an option for a synchronized block. The test As the JIT can optimise synchronized in ways a Lock cannot, I wanted to have a test which might demonstrate this and one which might "fool" the JIT. In this test, 25 million locks were performed between each of the threads. Java 6 update 26 was used. Threads 1x synch 1x Lock 1x AtomicInteger 2x synch 2x Lock ...