Distributed Unique Time Stamp Identifiers
Recently I published an article on using timestamps as unique identifiers, generated in a fraction of a microsecond. This article covers an implementation that supports distributed identifier generation directly.
This specific implementation supports up to one billion new 64-bit identifiers every second only repeating after 520 years. They can also be printed as timestamps containing the wall clock to make it easier to read.
Concurrent identifier generation in a distributed system
This TimeProvider assumes up to 100 hosts to produce different identifiers concurrently.
JVMs using the same hostId must be on the same physical machine using the same memory-mapped file,
or you can give each JVM a different hostId
A nano-second timestamp with a host identifier
This allows you to produce guaranteed unique identifiers, encoded with up to 100 sources, across up to 100 machines,
2021-12-28T14:07:02.954100128
Where the date/time/microseconds are the time and the last two digits are the host identifier, making it easier to see the source in the time stamp.
This gives a resolution of one-tenth of a microsecond (hundreds of nano-seconds) This is often the limit of the available wall clock in many systems anyway.
The hostId can be set as a system property by default on the command line with -DhostId=xx, or programmatically by calling the
DistributedUniqueTimeProvider.INSTANCE.hostId(hostId);
Speeding up the assignment with a host identifier
Having a preconfigured host identifier and keeping track of the most recent identifier in shared memory, allows fast concurrent generation of identifiers across machines.
Up to the theoretical limit of one billion per second.
The happy path is simple. Take the current time, remove the lower two digits and add the hostId. As long as this is higher than the last identifier, it’s ok. Should the machine fail and the information as to the last identifier be lost, the assumption is that the time taken to restart the service is enough time to ensure there is no overlap. If the service fails, but not the machine, the information is retained.
NOTE: This used the MappedFile in shared memory supported by Chronicle Bytes, an open-source library.

If the time hasn’t progressed, either due to high contention, or the wall clock going backwards e.g. due to a correction, a loop is called to find the next available identifier.
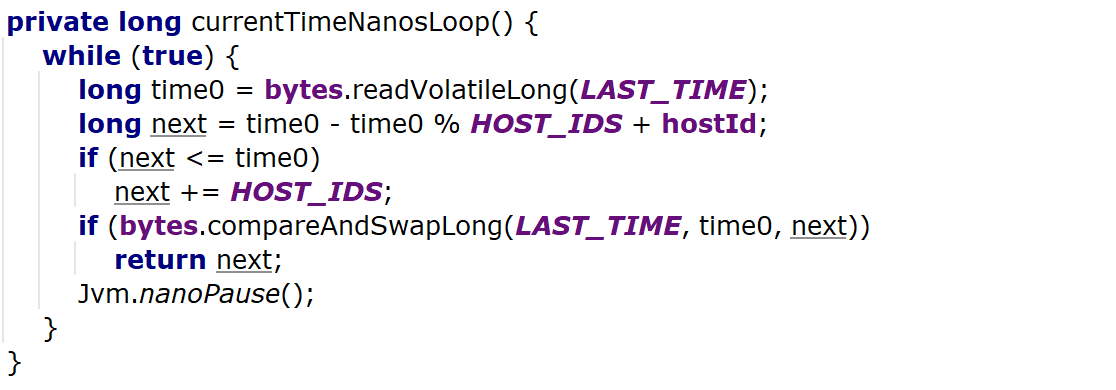
This loop looks for the next possible timestamp (with the hostId) and attempts to update it.
Using JMH to benchmark the timestamp provider
With JMH, benchmarking this utility in a single-threaded manner is pretty easy.

After less than five minutes, we get the following result on my windows laptop. You can get better results on a high-end server or desktop. The average time is around 37.4 nanoseconds. While this is single-threaded, this is generally on the unhappy path, as timestamps need to be at least 100 ns apart or they temporarily run ahead of the wall clock.
UUID.randomUUID() is also very fast, only six times longer, however, if you need a timestamp
and a source identifier for your event anyway, this is additional work/data.
On an i9-10980HK
Benchmark Mode Cnt Score Error Units
DistributedUniqueTimeProviderBenchmark.currentTimeNanos avgt 25 37.395 ± 0.391 ns/op
DistributedUniqueTimeProviderBenchmark.randomUUID avgt 25 207.709 ± 1.586 ns/op
On a Ryzen 9 5950X
Benchmark Mode Cnt Score Error Units
DistributedUniqueTimeProviderBenchmark.currentTimeNanos avgt 25 43.557 ± 0.801 ns/op
DistributedUniqueTimeProviderBenchmark.randomUUID avgt 25 265.285 ± 2.690 ns/op
Downsides
There are some advantages to using UUIDs.
It’s built-in and the extra overhead might not be a concern
No configuration is required
They are not predictable, the timestamp-based ones are highly predictable
Conclusion
You can have an 8-byte lightweight identifier that is unique across many hosts if you can use
some predetermined partitioning by host identifier. The identifier is still easily readable as text in
a slightly modified form of a timestamp.

Impressive scores in the benchmark! This is nice.
ReplyDeleteIn the browser there seems to be some rendering error (or could be a mistake?): "The hostId can be set as a system property by default on the command line with -DhostId=xx, or programmatically by calling the " (unfinished sentence). Would be useful to see the call you refer to.
Thanks for this post, very informative!
If you look at the JMH test setUp(), you can see the call. Unfortunately, its an image so I can't easily paste it here.
DeleteThank you for asking, I have added the missing code.
Delete